Een Kerstgedachte (sort-of)
 Het is bijna weer Kerstmis: een periode voor bezinning, gezellig met z’n allen voor de openhaard met warme wijn en veel zoetigheid. En als het goed is, is iedereen aardig tegen elkaar (dat is tenminste de verwachting). Maar hoe praten wij met Kerstmis met apparaten? En meer algemeen: hoe gaan we met Voice User Interfaces (VUI) om? Zien we deze steeds slimmere en persoonlijker apparaten steeds meer als persoonlijkheden en benaderen we ze dan ook zo, of blijven het in onze ogen gewoon dingen van metaal en kunststof en praten we ertegen zoals het ons uitkomt?
Het is bijna weer Kerstmis: een periode voor bezinning, gezellig met z’n allen voor de openhaard met warme wijn en veel zoetigheid. En als het goed is, is iedereen aardig tegen elkaar (dat is tenminste de verwachting). Maar hoe praten wij met Kerstmis met apparaten? En meer algemeen: hoe gaan we met Voice User Interfaces (VUI) om? Zien we deze steeds slimmere en persoonlijker apparaten steeds meer als persoonlijkheden en benaderen we ze dan ook zo, of blijven het in onze ogen gewoon dingen van metaal en kunststof en praten we ertegen zoals het ons uitkomt?
De populariteit van spraakgestuurde diensten is, vooral dankzij Amazon’s Alexa, het afgelopen jaar enorm gestegen en zal nu zowel Amazon als Google hebben aangekondigd vanaf het voorjaar van 2018 ook Nederlands te gaan ondersteunen alleen maar toenemen.
 In een interessant artikel op Medium gaat Cheryl Platz uitgebreid in op de manier waarop we met onze VUI’s zouden moeten, kunnen of willen “communiceren”.
In een interessant artikel op Medium gaat Cheryl Platz uitgebreid in op de manier waarop we met onze VUI’s zouden moeten, kunnen of willen “communiceren”.
Het artikel is uiteraard vanuit Amerikaans perspectief geschreven wat inhoudt dat de veronderstelde beleefdheidsnormen een stuk hoger liggen dan wij in Nederland gewend zijn. Ze schrijft dat in haar tijd bij Amazon ze ongeveer eens per maand een mail van verontruste ouders kregen met als strekking: "Mijn kinderen zijn onbeleefd tegen Alexa. Wij vinden dat Alexa alleen moet reageren als de kinderen er “a.u.b.” bij zeggen" (bv. “Alexa, turn on the lights please”)!
De ouders, zo bleek uit de verschillende mails, vonden het niet per se verkeerd om zo tegen een machine te praten, maar maakten zich zorgen over het aanleren van ongewenst gedrag: “Als ze dit leren dan gaan ze straks ook zo tegen mensen praten”!
Lokaliseren
Natuurlijk, dit “geplease” is heel Amerikaans en Cheryl geeft zelf al aan dat beleefdheid, hoewel als concept universeel, in de uitvoering ervan van land-tot-land sterk kan verschillen en dat implementatie van zo’n beleefdheidsmodule in het beste geval een kostbaar en glibberig concept zal zijn. Verder is beleefdheid ook sterk sociaal bepaald. Want als mijn 20-jarige neefje op bezoek is en mij op een vriendelijke toon vraagt “Oom Arjan, mag ik een biertje?”, dan hoeft er wat mij betreft zeker geen a.u.b. achter, maar als dezelfde vraag van een mij grotendeels onbekende student komt, ligt dat toch iets anders.
Maar hoe zit dat nu wanneer we met “apparaten” spreken via de steeds betere en steeds meer gepersonaliseerde VUI’s? Willen we dan dat “men” beleefd is tegen zo’n apparaat en zo ja waarom?
Een dikwijls gehoord argument is dat door gebruikers te stimuleren beleefd te zijn (tegen apparaten) ze ook eerder beleefd tegen anderen zullen zijn en dat is dan goed voor de maatschappij. Interessante gedachte maar is het ook zo?
Nederlanders versus Duitsers
Een aantal jaren geleden deden we een evaluatie van de dialogen in het Europese project ARISE over gesproken treintijden (“Ik wil morgenochtend om 10:00 uur van Utrecht naar Enschede”). Wat opviel was dat de Duitsers veel beleefder waren dan de Nederlanders. Ze begonnen een vraag dikwijls met “Bitte” en als eenmaal de juiste informatie gegeven was (“De trein vertrekt om 10:05 uur van perron 14”) dan werd het systeem daadwerkelijk beleefd bedankt “vielen Dank und auf Wiedersehen”. Nederlanders daarentegen hingen meestal direct op nadat ze gehoord hadden wat ze wilden weten.
Maar waarom zou je nu een VUI willen bedanken? Die computer maakt het echt niets uit! Blijkbaar is beleefd zijn iets dat bij Duitsers is ingebakken en bij ons (ietsje) minder aanwezig is.
Maar terug naar de vraag: willen we dat men beleefd omgaat met VUI”s en zo ja, hoe gaan we dat dan regelen?
Afdwingen van beleefdheid
 Wanneer we de mensheid willen opvoeden en proberen af te dwingen dat men beleefd tegen apparaten spreekt, dan kunnen we dat proberen te doen door interactief te reageren op de manier waarop de vraag gesteld wordt. Stel dat je Microsofts Cortana het volgende vraagt:
Wanneer we de mensheid willen opvoeden en proberen af te dwingen dat men beleefd tegen apparaten spreekt, dan kunnen we dat proberen te doen door interactief te reageren op de manier waarop de vraag gesteld wordt. Stel dat je Microsofts Cortana het volgende vraagt:
“Cortana, zet de wekker op 7 uur ’s morgens”. Dan kunnen systemen grofweg op de volgende 4 manieren reageren:
- Niet antwoorden. Als men de vraag niet beleefd stelt, gewoon niet doen wat er gevraagd werd, maar aangeven dat een “alstublieft” verwacht wordt.
Cortana: “je bedoelt alsjeblieft?” - Positieve feedback. Wel reageren maar aangeven dat het ook beleefd gevraagd had kunnen worden.
Cortana: “Alsjeblieft, de wekker staat ingesteld op 7 uur in de ochtend!” - Positieve stimulatie. Wel doen wat er gevraagd werd, maar ook laten weten dat het anders gevraagd had kunnen worden.
Cortana: “De wekker staat op 7 uur. Aardig dat je het zo beleefd vraagt!” - Spiegelen. Op dezelfde manier antwoorden als de vraag gesteld wordt.
Cortana: “Staat op 7 uur!”
De eerste drie vormen komen op mij wat prekerig over en zeker als je hoofd er niet naar staat, kan het tot een enorme ergernis leiden als zo’n (stomme) computer niet doet wat je wilt omdat je het niet aardig vraagt. Maar… wellicht dat het bij kinderen toch zou helpen om hen in ieder geval te laten realiseren dat het ook beleefd gevraagd had kunnen worden.
Spiegelen
Persoonlijk zou ik het liefst zien dat de computer mijn gedrag spiegelt. Als ik haast heb of om wat voor redenen dan ook mijn hoofd er niet naar staat, dan zou ik het niet erg vinden om op een bruusk gestelde vraag een dito bruuske reactie te krijgen. Ik heb haast, stel een korte vraag en wil waarschijnlijk snel een korte reactie.
Als ik daarentegen vrolijk ben en de computer op een beleefde wijze een vraag stel, dan wil ik waarschijnlijk ook wel op zo’n wijze beantwoord worden: “Hee Cortana, zou je alsjeblieft de wekker op morgenochtend 7 uur willen zetten?” -> “Ha Arjan, ik heb het gedaan hoor. Om 7 uur loopt ie af. Moet ik nog iets anders doen?” -> “Hee Cortana, nee hoor en bedankt”.
 Die laatste conversatie klinkt wellicht wat overdreven, maar omdat bijna alle huidige VUI’s pas reageren als je eerst het activeringswoord uitspreekt (Hee Cortana, Hi Alexa, OK Google), moet je dat wel doen. Alleen “Nee hoor en bedankt” leidt dan ook tot niets.
Die laatste conversatie klinkt wellicht wat overdreven, maar omdat bijna alle huidige VUI’s pas reageren als je eerst het activeringswoord uitspreekt (Hee Cortana, Hi Alexa, OK Google), moet je dat wel doen. Alleen “Nee hoor en bedankt” leidt dan ook tot niets.
Maar die keuze tot spiegelen is persoonlijk en je kunt je voorstellen dat organisaties met een eigen stijl (bv IKEA met het hun typerende “je” en “jij”) altijd op een hun eigenwijze willen doen.
Realisering
Maar stel nu dat we dat spiegelen inderdaad zouden willen, hoe doen we dat dan?
Het is waarschijnlijk niet eenvoudig om iedereen op precies dezelfde manier als waarop de vraag gesteld wordt te antwoorden. Maar we zouden wel bijvoorbeeld drie beleefdheidscategorieën kunnen definiëren (onbeleefd, neutraal, beleefd) en iedere gestelde vraag met een van deze categorieën kunnen labelen. Wanneer het niet helemaal duidelijk is in welke categorie een vraag thuishoort, kies je voor de zekerheid de hoogste.
Het toekennen van een categorie kan gedaan worden middels woorden en tijdsduur. Wanneer bepaalde woorden wel of juist niet aanwezig zijn (hallo, goedemorgen, alsjeblieft, etc.) en wanneer de gemiddelde tijdsduur van de vraag onder of juist boven de gemiddelde duur ligt, dan zijn dat indicatoren voor de manier waarop de vraag gesteld werd.
De VUI kan dan besluiten om, indien mogelijk, op eenzelfde wijze te reageren. Wel houdt het in dat de verschillende wijzen om te reageren voorgeprogrammeerd moeten worden en dat is waarschijnlijk een hoop extra werk.
Huidige status
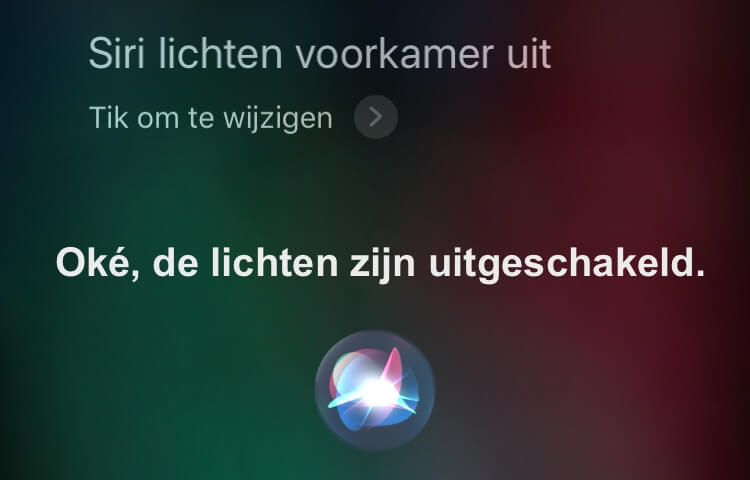
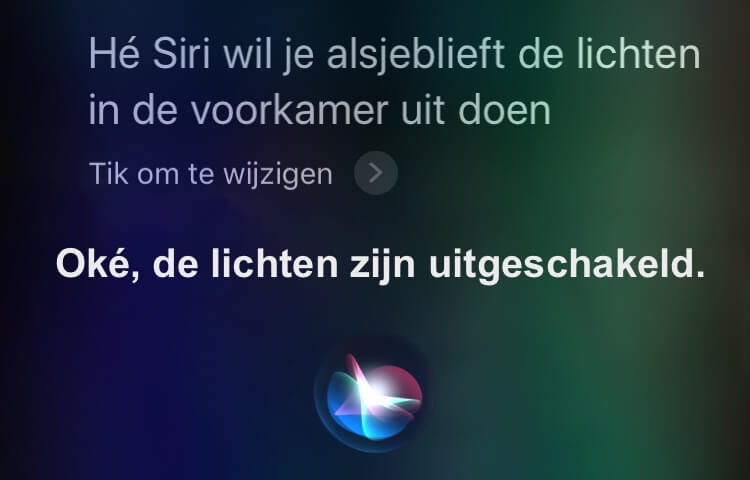
Hoe doen de huidige VUI’s het nu? Waarschijnlijk doen ze niets met de wijze waarop de opdracht gesteld werd zoals deze twee screenshots laten zien. In beide gevallen werden de lichten keurig uitgedaan.
 |
 |
|
De reactie van SIRI is onafhankelijk van de manier waarop je het vraagt. |
|
Tone of voice
Wat vooralsnog buiten beschouwing blijft is de “tone-of-voice”: de vocale realisatie van de gestelde vraag. Wij mensen kunnen hier makkelijk mee spelen en daardoor ook een korte vraag toch op een aardige manier stellen. Denk aan “Hee, heb je de garage gebeld?” dat je op verschillende manieren kunt uitspreken. Maar een goede analyse van deze tone-of-voice is niet eenvoudig en bovendien spelen hier de verschillende manieren waarop dit in de verschillende landen en sociale groepen gedaan wordt een grote rol. Voorlopig maar afblijven dus. Maar zo’n simpele, spiegelende VUI lijkt me wel wat.
Conclusie
Het zeer lezenswaardige artikel van Cheryl Platz is duidelijk vanuit een Amerikaanse context geschreven. In de Verenigde Staten is men waarschijnlijk meer dan bij ons in Nederland gericht op beleefdheid bij het voeren van een conversatie en dus is het te verwachten dat ouders zich zorgen maken over de in hun ogen onbeleefde manier waarop kinderen tegen VUI’s zoals Alexa of Siri kunnen spreken. In Nederland kijken we waarschijnlijk iets losser tegen deze veronderstelde degeneratie van de omangsvormen aan, maar het is de vraag of ouders echt zitten te wachten op tegen Siri vloekende pubers. Zeker met Kerstmis iets om bij stil te staan.
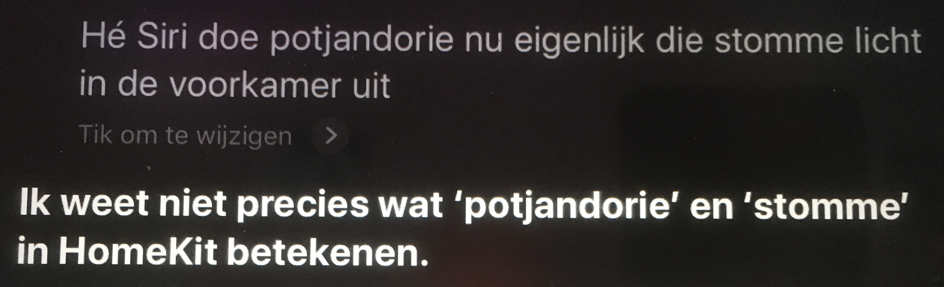 Als je “verkeerde” taal gebruikt dan herkent SIRI dat uitstekend, maar ze kan er niets mee zoals uit haar reactie blijkt.
Als je “verkeerde” taal gebruikt dan herkent SIRI dat uitstekend, maar ze kan er niets mee zoals uit haar reactie blijkt.

 De term Onttovering werd gemunt door de Duitse socioloog Max Weber die in de 19de eeuw zag dat wetenschappelijke verklaringen steeds meer de plek van geloof en magie gingen overnemen. En naarmate de wetenschap steeds wijder verbreid werd, nam het onttoveren toe. Denk bijvoorbeeld aan de bliksem waarvan men vroeger in Noord-Europa dacht dat het kwam van Thor, de dondergod, die zwaaiend met zijn hamer rondreed door de hemel. Het bleek uiteindelijk net iets ander te liggen.
De term Onttovering werd gemunt door de Duitse socioloog Max Weber die in de 19de eeuw zag dat wetenschappelijke verklaringen steeds meer de plek van geloof en magie gingen overnemen. En naarmate de wetenschap steeds wijder verbreid werd, nam het onttoveren toe. Denk bijvoorbeeld aan de bliksem waarvan men vroeger in Noord-Europa dacht dat het kwam van Thor, de dondergod, die zwaaiend met zijn hamer rondreed door de hemel. Het bleek uiteindelijk net iets ander te liggen.