De “Spraakboys” van NOTaS (UTwente, Radboud Universiteit en Telecats) zijn de laatste tijd zeer actief op het gebied van spraakherkenning: niet alleen met pilots, onderzoek of demo’s maar nu met echte toepassingen. Hieronder een overzicht van de verschillende activiteiten op het gebied van ASR in en buiten Nederland.
Natuurlijk: spraakherkenning is er al een tijdje en wordt (bv door Telecats) al jarenlang gebruikt voor “vraag-antwoord-dialogen” in de call centre wereld. Maar met de komst van AI en het gebruik ervan voor spraakherkenning (vanaf ± 2010) is de algemene herkenning zoveel beter geworden, dat grootschalige toepassingen eenvoudig mogelijk worden.
![]() Op de workshop “Low Development Cost, High Quality Speech Recognition for New Languages and Domains” op de Johns Hopkins University in 2009 besloten een groepje enthousiaste ASR-ontwikkelaars de handen in een te slaan en een “Open Source AI ASR-systeem” te ontwikkelen: KALDI. Het duurde nog even voordat dit initiatief bij “iedereen” bekend was maar sinds een aantal jaren wordt er door verschillende ontwikkelaars in verschillende landen hard gewerkt om een “KALDI-herkenner” ook voor hun taal beschikbaar te maken.
Op de workshop “Low Development Cost, High Quality Speech Recognition for New Languages and Domains” op de Johns Hopkins University in 2009 besloten een groepje enthousiaste ASR-ontwikkelaars de handen in een te slaan en een “Open Source AI ASR-systeem” te ontwikkelen: KALDI. Het duurde nog even voordat dit initiatief bij “iedereen” bekend was maar sinds een aantal jaren wordt er door verschillende ontwikkelaars in verschillende landen hard gewerkt om een “KALDI-herkenner” ook voor hun taal beschikbaar te maken.
In Nederland besloten de Nederlandse Politie, het Instituut voor Beeld en Geluid en de Universiteit Twente “botje-bij-botje” te leggen en Laurens vd Werff (net teruggekeerd van een Postdoc verblijf in Reykjavik) te vragen een Nederlandse KALDI-herkenner te maken. Zo-gezegd-zo-gedaan en sinds een krap jaar is de herkenner beschikbaar.
Narratieven
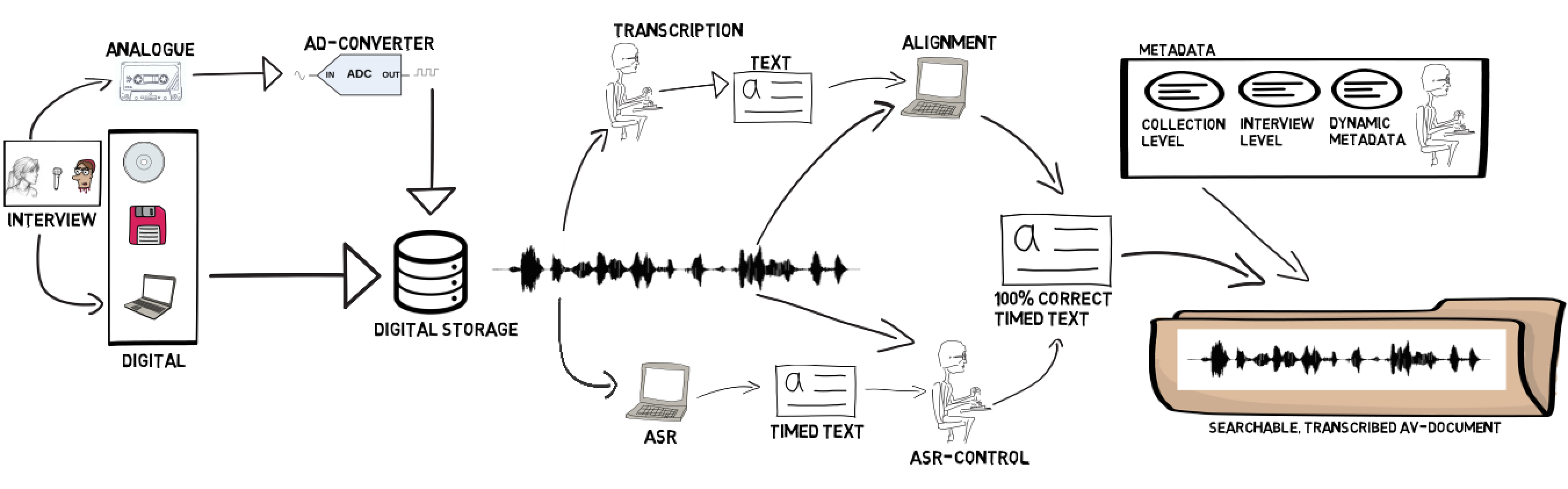
Zowel binnen als buiten de onderzoekswereld worden er verschrikkelijk veel “gesprekken” opgenomen. Je moet daarbij denken aan alle redevoeringen en interrupties in het Nederlandse Parlement, Raadvergaderingen in de gemeenten of Provinciale Staten, colleges, verhoren door de Politie of de FIOD, RTV-uitzendingen, verhalen van “gewone” mensen over hun leven of (speciale) gebeurtenissen waar zij bij waren, preken in de kerken en eindeloos veel meer.
Niet alles is natuurlijk even relevant en moet voor de eeuwigheid bewaard worden, maar veel is wel de moeite waard om op z’n minst een tijdje te bewaren. Het nadeel van veel van dit soort “gesprekken” (ofwel narratieven) is dat ze moeilijk vindbaar en ontsluitbaar zijn.
Waar gaat het over?
Vaak bestaat er van een opgenomen narratief slechts een summiere hoeveelheid metadata: de titel, datum van opname/uitzending, de sprekers en, als je geluk hebt, een korte samenvatting. Maar wat er daadwerkelijk gezegd werd, is meestal niet bekend en kan alleen gekend worden door de opname af te luisteren.
Het is dan al lang een terugkerende vraag aan spraakherkenningsonderzoekers: “he, wanneer kunnen jullie dit nou eens goed herkennen?”
Nou, met enige mitsen-en-maren: dat kan.
Oral History
Een van de onderzoeksgebieden waar veel gebruik gemaakt wordt van narratieven is Oral History. Mensen worden gevraagd te vertellen over hun leven en/of speciale gebeurtenissen waar ze bij waren. Alles dat ze zeggen wordt opgenomen, volledig uitgeschreven en minutieus geanalyseerd. Daarbij gaat het er niet alleen om wat ze zeggen, maar dikwijls ook om hoe ze het zeggen. Waar aarzelen mensen, waar pauzeren ze, welke niet-afgemaakte woorden gebruiken ze etc. etc.
Transcriberen
 Workshop in Arezzo alwaar de verschillende spraakherkenners met elkaar werden vergeleken en bekeken werd hoe die herkenners voor OH-onderzoekers zinvol zouden kunnen worden ingezet. Het zo gedetailleerd uitwerken (=verbatim transcriberen) van een interview is echter een monnikenklus: een uur opnamen kost tussen de 6 en de 8 uur uitwerktijd. En doordat er dikwijls niet veel geld beschikbaar is, wordt vaak nagelaten de opnamen volledig uit te schrijven. Hierdoor zijn de interviews weer minder goed vindbaar en kan een andere onderzoeker niet direct zien of zo’n interview wellicht ook voor hem/haar geschikt zou kunnen zijn.
Workshop in Arezzo alwaar de verschillende spraakherkenners met elkaar werden vergeleken en bekeken werd hoe die herkenners voor OH-onderzoekers zinvol zouden kunnen worden ingezet. Het zo gedetailleerd uitwerken (=verbatim transcriberen) van een interview is echter een monnikenklus: een uur opnamen kost tussen de 6 en de 8 uur uitwerktijd. En doordat er dikwijls niet veel geld beschikbaar is, wordt vaak nagelaten de opnamen volledig uit te schrijven. Hierdoor zijn de interviews weer minder goed vindbaar en kan een andere onderzoeker niet direct zien of zo’n interview wellicht ook voor hem/haar geschikt zou kunnen zijn.
Taalafhankelijk
Een bijkomend probleem is de gesproken taal. Bijna alle onderzoekers beheersen naast hun eigen taal het Engels en vaak nog een derde taal maar (bijna) niemand beheerst alle talen van potentieel interessante narratieven. Het zou geweldig zijn als je (geheel automatisch) van de transcripties een ruwe vertaling (in je eigen taal of het Engels) zou kunnen krijgen om op basis daarvan te besluiten of een echte vertaling de moeite waard zou zijn.
Omdat zowel de automatische spraakherkenning als het automatisch vertalen door de inzet van kunstmatige intelligentie de laatste jaren zo’n enorme performance boost hebben gekregen, werd er in mei 2017 in Arezzo een Oral History and Technology workshop gehouden om de (on)mogelijkheden van de technologie en de eisen en wensen van gebruikers (Oral Historians) in kaart te brengen en op elkaar af te stemmen. Het achterliggende doel van de workshop was om tot een plan-van-aanpak te komen voor een web-portal waarmee onderzoekers hun audiovisuele data snel, goedkoop en makkelijk zouden kunnen transcriberen en (eventueel) vertalen.
Een uitgebreid verslag (door Stef Scagliola) van deze succesvolle workshop is te vinden op de website van CLARIAH.
 Webportal van het CLST voor de Nederlandse spraakherkenning (Algemeen en OH)
Webportal van het CLST voor de Nederlandse spraakherkenning (Algemeen en OH)
Terug naar het Nederlands
Om in Arezzo de stand van zaken in Nederland te laten zien, was er door het CLST in de weken voorafgaand aan de workshop, hard gewerkt aan de Nederlandse Portal. Dit resulteerde in een eenvoudige doch bruikbare portal waarmee (geregistreerde) onderzoekers hun audiovisuele opnamen kunnen laten transcriberen.
Gaat dit foutloos? Nee! Maar, mits de sprekers duidelijk en niet door elkaar spreken, er geen of weinig achtergrondlawaai is en de woorden “gewoon” Nederlands zijn (niet veel jargon, eigennamen of afkortingen) werkt het wel heel goed. Kijk maar eens bij de voorbeelden op het einde van dit artikel.
Taalmodel
Een van de zaken die voor verbetering vatbaar zijn, is het zgn Taalmodel: een statistisch model dat de woorden bevat die herkend moeten worden en dat de kans berekend op woord-C, gegeven de woorden A en B. Om de herkenning zo goed mogelijk te krijgen, moet zo’n model een afspiegeling zijn van de spraak zoals gesproken binnen een bepaalde context. Hoe beter deze afspiegeling is, hoe meer de woorden en zinsconstructies lijken op hetgeen er gezegd zal worden, hoe beter de herkenning.
OH-taalmodel
Een taalmodel voor interviews met mensen over hun belevenissen tijdens WOII moet bv. woorden als concentratiekamp, Führer, Nazi’s en hongerwinter bevatten, terwijl dat voor een taalmodel om interviews over de staat van het Nederlandse onderwijs te transcriberen, minder nodig is: daar zijn juist andere woorden en afkortingen relevant.
Voor de workshop in Arezzo werd door het CLST en de UTwente met materiaal van het Getuigenverhalenproject (NIOD) een Nederlands OH-model gemaakt mbv grote hoeveelheden teksten over de Tweede Wereldoorlog. Dit taalmodel zorgde direct al voor een flink betere herkenning van met name "oude woorden".
Een goed taalmodel is, naast een goed akoestisch model, beslissend voor de mate waarin spraak herkend kan worden. En voor de hier beschreven Nederlandse KALDI-herkenner ook door niet-ASR-specialisten succesvol gebruikt kan worden, moet er de mogelijkheid geschapen worden om zelf (wellicht met enige steun) een taalmodel te kunnen maken.
Toepassingen
Op dit moment worden de Nederlandse spraakherkenners door verschillende partijen (allemaal NOTaS-deelnemers) gebruikt om te laten zien dat de lang gekoesterde droom van “Goede Spraakherkenning” realiteit wordt.
Hieronder een aantal voorbeelden van verschillende soorten narratieven waarbij ASR werd gebruikt om de transcripties met tijdinformatie (van ieder herkend woord is bekend wanneer het uitgesproken werd) te maken.
{slider=NOTaS-MuZIEum video}
![]() Naar aanleiding van de feestelijke lancering van “Taal- en Spraaktechnologie voor mensen met een visuele handicap” in het MuZIEum in Nijmegen, werd een interview gehouden met MuZIEum-directeur Heleen Vermeulen en NOTaS-voorzitter Staffan Meij. De ondertitels zijn geheel automatisch gegenereerd en niet door mensen gecorrigeerd.
Naar aanleiding van de feestelijke lancering van “Taal- en Spraaktechnologie voor mensen met een visuele handicap” in het MuZIEum in Nijmegen, werd een interview gehouden met MuZIEum-directeur Heleen Vermeulen en NOTaS-voorzitter Staffan Meij. De ondertitels zijn geheel automatisch gegenereerd en niet door mensen gecorrigeerd.
{/slider}
{slider=Nachtmispreek}
![]() Omdat met name ouderen nogal eens moeite hebben me het volgen van de preek tijdens de mis, werd een test gedaan om te zien of spraakherkenning ook zou werken in een galmende omgeving (de kerk) waarbij er veel langzamer dan gebruikelijk wordt gesproken. Hier de preek van Vicaris Woolderink tijdens de kerstnachtmis van 2016.
Omdat met name ouderen nogal eens moeite hebben me het volgen van de preek tijdens de mis, werd een test gedaan om te zien of spraakherkenning ook zou werken in een galmende omgeving (de kerk) waarbij er veel langzamer dan gebruikelijk wordt gesproken. Hier de preek van Vicaris Woolderink tijdens de kerstnachtmis van 2016.
{/slider}
{slider=Spraaktechnologie en Oral History}
![]() Interview met Henk van den Heuvel tijdens de Arezzo-workshop over zijn beweegredenen om juist als spraaktechnoloog met Oral Historians samen te werken. De enige correctie in de verder automatisch gegenereerde transcriptie is het vervangen van “spraaktechnologie” (werd wel herkend) door “spraaktechnoloog” (werd niet herkend want stond niet in het taalmodel). Het interview met de Nederlandse Henk, de Italiaanse Silvia en de Engelse Louise, werd eerst herkend door de resp. Nederlandse, Italiaanse en Engelse spraakherkenner en vervolgens mbv Google Translate omgezet in de andere twee talen. De vertaling is dus gebaseerd op ongecorrigeerde herkenning!
Interview met Henk van den Heuvel tijdens de Arezzo-workshop over zijn beweegredenen om juist als spraaktechnoloog met Oral Historians samen te werken. De enige correctie in de verder automatisch gegenereerde transcriptie is het vervangen van “spraaktechnologie” (werd wel herkend) door “spraaktechnoloog” (werd niet herkend want stond niet in het taalmodel). Het interview met de Nederlandse Henk, de Italiaanse Silvia en de Engelse Louise, werd eerst herkend door de resp. Nederlandse, Italiaanse en Engelse spraakherkenner en vervolgens mbv Google Translate omgezet in de andere twee talen. De vertaling is dus gebaseerd op ongecorrigeerde herkenning!
{/slider}
{slider=Wie remt de robot?}
![]() Een interessant interview in de Nieuwsshow met de Tilburgse hoogleraar Pieter Spronck (Computer Science) nav zijn Oratie over de “Veiligheidsmaatregelen Kunstmatige intelligentie”. Het interview (de geïnterviewde en 2 interviewers) werd door de herkenner gehaald en ongecorrigeerd op de site geplaatst. De presentatie is in de zgn “Karaoke stijl” waarbij de gehele tekst wordt getoond en het uitgesproken woord wordt benadrukt (onderstreept en geel).
Een interessant interview in de Nieuwsshow met de Tilburgse hoogleraar Pieter Spronck (Computer Science) nav zijn Oratie over de “Veiligheidsmaatregelen Kunstmatige intelligentie”. Het interview (de geïnterviewde en 2 interviewers) werd door de herkenner gehaald en ongecorrigeerd op de site geplaatst. De presentatie is in de zgn “Karaoke stijl” waarbij de gehele tekst wordt getoond en het uitgesproken woord wordt benadrukt (onderstreept en geel).
{/slider}
{slider=Debat Gemist}
![]() Spraakherkenning wordt ook ingezet voor het oplijnen van audio en tekst. De plenaire debatten van de Tweede Kamer worden op deze manier automatisch ondertiteld. De griffie van de Tweede Kamer levert de officiële teksten aan (de door de griffie uitgeschreven handelingen), de spraakherkenner berekent van ieder woord wanneer het werd uitgesproken en een ondertitelingsalgoritme maakt vervolgens de ondertitels. De geschreven tekst is “grammaticaal correct Nederlands” en komt daarom niet altijd overeen met de daadwerkelijk gesproken tekst.
Spraakherkenning wordt ook ingezet voor het oplijnen van audio en tekst. De plenaire debatten van de Tweede Kamer worden op deze manier automatisch ondertiteld. De griffie van de Tweede Kamer levert de officiële teksten aan (de door de griffie uitgeschreven handelingen), de spraakherkenner berekent van ieder woord wanneer het werd uitgesproken en een ondertitelingsalgoritme maakt vervolgens de ondertitels. De geschreven tekst is “grammaticaal correct Nederlands” en komt daarom niet altijd overeen met de daadwerkelijk gesproken tekst.
{/slider}
Conclusie
 Met de komst van AI in het algemeen en de KALDI-toolkit in het bijzonder, zijn er grote stappen gemaakt op het gebied van Automatische Spraakherkenning. ASR werkt ook al geldt dat nog niet voor alle situaties en sprekers. Kinderen en sprekers met een zwaar accent zijn nog steeds moeilijk te herkennen en ook gesprekken waarin mensen door elkaar spreken of waar een sterk afwijkend taalgebruik wordt gebezigd, worden duidelijk suboptimaal herkend.
Met de komst van AI in het algemeen en de KALDI-toolkit in het bijzonder, zijn er grote stappen gemaakt op het gebied van Automatische Spraakherkenning. ASR werkt ook al geldt dat nog niet voor alle situaties en sprekers. Kinderen en sprekers met een zwaar accent zijn nog steeds moeilijk te herkennen en ook gesprekken waarin mensen door elkaar spreken of waar een sterk afwijkend taalgebruik wordt gebezigd, worden duidelijk suboptimaal herkend.
Deze problemen kunnen deels getackeld worden door betere akoestische modellen, deels door betere taalmodellen die bij voorkeur “on-the-fly” door eindgebruikers kunnen worden aangepast.
Maar dat ASR niet meer weg te denken is uit onze samenleving blijkt wel uit de enorme hoeveelheid toepassingen van ASR in onze moderne wereld. Omdat 85% van de mensen op Facebook de video’s zonder geluid bekijkt, heeft Facebook besloten gewoon alle video’s automatisch te ondertitelen (anders zappen de mensen weg) en ook Google biedt al jarenlang de mogelijkheid om je eigen video’s automatisch te ondertitelen, te corrigeren en opnieuw te uploaden.
Gecombineerd met de steeds betere automatische vertalingen wordt het steeds makkelijker om het enorme potentieel aan AV-content op het net, voor iedereen te ontsluiten.