
 Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. The developer of Whisper, OpenAI, shows that the use of such a large and diverse dataset leads to improved robustness to accents, background noise and technical language. Moreover, it enables transcription in multiple languages, as well as translation from those languages into English. The 9 models are open-source and can be downloaded.
Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. The developer of Whisper, OpenAI, shows that the use of such a large and diverse dataset leads to improved robustness to accents, background noise and technical language. Moreover, it enables transcription in multiple languages, as well as translation from those languages into English. The 9 models are open-source and can be downloaded.
To my knowledge, Whisper is a very good (and probably the best) ASR engine for now and it can be used as a foundation for building useful applications and for further research on robust speech processing. It was launced in September 2022 and is gaining a lot of positive response.
Privacy
In many cases where AV-recordings are made, privacy can be an important item. Especcialy when the recordings are "sensitive" the interviewer (or owner of the recordings) must take care about a carefull handling of the recodings. Whisper can easily run on a fast and big server, on your own, small laptop and on any device between these two. The recognition will give an equal result. The only real difference is the processing speed of Whisper: the better your computer (and especially when it has a graphical card) the faster the recognition.
So, certainly for people who have a fast computer and who occasionally do have sensitive date, we always recommend installing it at least on your own system as well in order to avoid the risk of data breach.
Is ASR ready?
No! At this moment (June 2023) there are still a few drawbacks to Whisper such as the lack of diarization (knowing which speaker is speaking) and the sometimes overly fancy result ("I um I, I thought I'd do that for a moment" is usually recognised by Whisper as "I thought I'd do that for a moment").
This last effect is probably caused by the fact that Whisper uses the chatGPT-alike language model to "translate" the recognition into a well-running sentence. This is excellent for transcribing most speech but may not always be desirable for the research of speech and/or dialogues where hesitations, pauses, repetitions and other disfluencies are the topic of research.
On diarization and a more literal transcription of speech, several researchers are working hard. When something more is known about its capabilities and how to use it yourself, we will let it know.
Set-up Whisper
Whisper came out as a Python script. After installing Python (version 3.9 - 3.10) you need to install PyTorch (1.10.1) and FFMPEG.
Once done, you can download and install (or update to) the latest release of Whisper with the following command:
pip install -U openai-whisper
For more information about this, see here.
Available models and languages
There are five model sizes, four with English-only versions, offering speed and accuracy tradeoffs. Below are the names of the available models and their approximate memory requirements and relative speed.
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en |
tiny |
~1 GB | ~32x |
| base | 74 M | base.en |
base |
~1 GB | ~16x |
| small | 244 M | small.en |
small |
~2 GB | ~6x |
| medium | 769 M | medium.en |
medium |
~5 GB | ~2x |
| large | 1550 M | N/A | large |
~10 GB | 1x |
The .en models for English-only applications tend to perform better, especially for the tiny.en and base.en models. OpenAi observed that the difference becomes less significant for the small.en and medium.en models.
Performance
Whisper's performance varies widely depending on the language and the model. The figure below shows a WER (Word Error Rate) breakdown by languages of the Fleurs dataset using the large-v2 model (The smaller the numbers, the better the performance). Additional WER scores corresponding to the other models and datasets can be found on the Whisper website. For more information, see her.

License
Important: Whisper's code and model weights are released under the MIT License. See LICENSE for further details.
Windows
As explained before, Whisper runs with Python on al kind of different computers. In general installing the various components yourself is not very difficult for technically oriented people but can be a bit trickier for "ordinary" users. What you can do is to run a very short script in a Power Shell terminal.
Do the following:Open a Power Shell terminal and then type: iex (irm whisper.tc.ht)
All the things you needed to do by hand, will be done automatically! Once ready, you can run Whisper in the Power Shell terminal by for example typing:
whisper my_audio_file.mp4 --model medium --language nl --device cuda --output_dir "E:\Documenten\Projecten\Example"
This means that the AV-file my-audio_file.mp4 will be recognised in Dutch, the GPU is used, and the end results is stored in E:\Documenten\Projecten\Example.
SubtitleEdit
However, dedicated tools are made for Windows (and Mac and Linux). To run it on your own Windows PC, you can of course install Whisper as explained above, but if you just want to recognise a couple of AV-files, SubtitleEdit can be a good choice. SE originally was developped for subtitling Video files, but now you can use automatic speech recognition as well. It started with KALDI support and from version 3.6.11 Whisper is possible as well. SubtitleEdit is an open source project that can be downloaded here: https://www.nikse.dk/subtitleedit
MacOS
For Apples Macbook (Air and Pro) Whisper can of course be installed with Python but since February 2023 there is a very nice tool to run your recognitions: MacWhisper. You can download it for free from the Apple shop or from the developpers home page: https://goodsnooze.gumroad.com/l/macwhisper
If you are satisfied with its use, you can buy the Pro version (€18) to use the medium and large models as well.
One of the big advantages of the new Macs is that MacWhisper uses the GPU available in the M1 and M2 chip. Recognition then runs up to 10x faster.
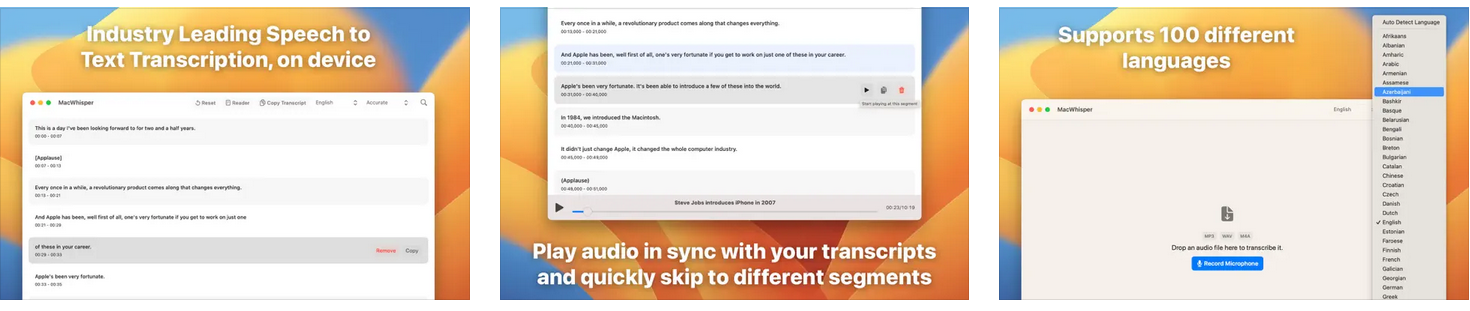
Beside the recognition, it offers additional options to correct recognition errors (for example replace Jansen -> Janssen) and other handy tools.
Whisper Results
Whisper, especially with the medium and large models, gives very good recognition results. However, the text is sometimes a little too good which certainly tends to improve readability, but makes the results slightly less suitable for linguistic research.
Translations
Whisper has the ability to translate the recognised speech directly into English. However, it turns out that if we recognise a Dutch text with German, English, or Italian, we see the transcriptions in those languages as well. Apparently, Whisper can do more in this area than they indicate. However, as you can see below, the German result, a language close to Dutch, is good, English is acceptable but Italian fails.
To compare with a state-of-the-art translator, we have added the translations of the Dutch text by DeepL below it.
Recognition and Translations by Whisper
| Dutch (recognition) | German (recog/translation) | English (recog/ranslation) | Italian (recog/translation) |
| Dank u wel, wethouder. Na de introductie ga ik door een aantal slides heen, waarin wellicht wat overlaps zit. Als u denkt, ze gaat te snel of ze gaat te langzaam, roep dan even. Dan kunnen we langer met elkaar in gesprek. Ik denk dat ik de heer Meijer niet moe voor te stellen. Op mijn rechterhand voor u links zit Mark van de Vliet. Hij is één van de externe projectleiders van Hefo. In dit geval dé externe projectleider van Hefo. die ons begeleiden bij de scenario-studie om te komen tot een in ieder geval gedegen verhaal. Mijn naam is Beert de Metz en ik heb in ieder geval voor hier het stokje overgenomen van Jan Derksen die u bij de vorige beeldvormende avond heeft gezien. En ik neem nu even de rol als projectleider van dit deel van het traject op. Even kijken, dit hebben we net al wel een soort van behandeld. Dit gaat over het ZBB-besluit en de besparing van 2 ton op de exploitatielasten van de huisvesting van de gemeentelijke organisatie in 2023 en vanaf 2024 2,5 ton. Onderzoek is verricht naar meer vierkante meters verhuren, dat bleek niet haalbaar. En toen is er onderzoek gedaan naar alternatieve mogelijkheden om toch tot die besparing te komen. Daar bent u op 15 november over geïnformeerd. Er waren er zes. Die zijn teruggebracht naar drie. Drie voorkeursscenario's. En daar is een marktconsultatie op losgelaten met als doel te kijken of iets haalbaar was. We hebben niet al die scenario's de markt opgebracht en gekeken. Gooi, hoe komt u eens met alle mogelijke offertes om het helemaal door te rekenen. Maar wat is haalbaar? En wat draagt bij aan het creëren van waarde in welke zin dan ook? Net zo goed als wat draagt bij aan het besparen op de exploitatielasten? 1 en 3 zijn in principe haalbaar. 2 is zeer onzeker. Dus zijn we verder gegaan met het uitwerken van in ieder geval 1 en 3. En bij 3 zullen we zo meteen laten zien waarom 3 in ons optiek het meeste de voorkeur geniet. Wat waren nou uitgangspunten waar wij mee aan de slag zijn gegaan? Dat is uiteraard het verlagen van die structurele last op de exploitatie. Dat was dus het ZBB-besluit uit 2021. |
Dankeschön, Vizepräsidentin. Nach der Introduktion gehe ich durch ein paar Slides, in denen vielleicht etwas überlappt ist. Wenn ihr denkt, sie geht zu schnell, oder sie geht zu langsam, dann ruft dann kurz. Das können wir länger miteinander in Gesprächen. Ich denke, dass ich den Herrn Mayer nicht mehr vorstelle. Auf meiner rechten Hand, vor euch links, steht Mark van der Vliet. Er ist einer der externe Projektleiter von Hefo. In diesem Fall der externe Projektleiter von Hefo. die uns begeleiten bei der Szenario-Studie, um zu kommen, dass es ein gedegenes Verhältnis gibt. Mein Name ist Behrte Metz, und ich habe hier den Stokken von Jan Derksen, die Sie bei der vorigen Bildformende Abend gesehen haben, übernommen. Und ich nehme nun die Rolle als Projektleiter von diesem Teil des Trajekts auf. Schauen wir mal, das haben wir gerade schon einiges behandelt. Es geht um die ZBB-Beschläge, eine Besparung von 2 Tonnen auf den Exploitationen von der Häusfestung der öffentlichen Organisation in 2023 und ab 2024 2,5 Tonnen. Die Untersuchung wurde nach mehr Vierkantemetern verhüren, das war nicht erlaubt. Und dann wurde die Untersuchung nach alternativen Möglichkeiten gemacht, um trotzdem zu dieser Besparung zu kommen. Da sind Sie auf den 15. November darüber informiert. Es waren sechs. Die sind zurückgebracht nach drei. Drei Vorcursszenario's. Da ist eine Marktkonsultation losgelaten, mit als Ziel, zu schauen, ob etwas erhaltbar war. Wir haben nicht alle die Szenario's der Markt aufgebracht und geschaut, gooi, oh, komm, du bist mit allen möglichen Offertes, um es komplett durchzureknen, aber was ist erhaltbar? Und was trägt bei an das Krieren von Werten, in welchem Sinne auch? Net so gut als, was trägt bei an das Sparen auf die Explotatielasten? 1 und 3 sind in Prinzip erhebbar, 2 sehr unsicher, also sind wir weitergegangen mit dem Ausarbeiten von 1 und 3. Bei 3 werden wir gleich sehen, warum 3 in unserer Optik den meisten Vorkur genießen. Was waren nun die Ausgangspunkte, mit denen wir an den Schlag gegangen sind? Das ist natürlich das Verlagen von den strukturellen Kosten auf die Exploitation. Das war das ZBB-Bescheid aus 2021. |
After the introduction, I will go through a number of slides in which there may be some overlap. |
Grazie, leggera. Dopo l'introduzione andrò in un paio di slides in cui forse c'è alcun risultato. Se pensate che si fa troppo velocemente o troppo velocemente, chiedeteci. Ci parleremo più tempo. Penso che non posso mostrare il signore Mayer. A mia right-hand for your left is Mark van der Vliet. He is one of the external project leaders of HEVO. In this case, THE external project leader of HEVO. che ci aiuterà alla studia di scenario per arrivare a un vero vero storico. Mi chiamo Beert de Metz, e in questo modo ho preso il posto di Jan Derkse, che vi ha visto nel precedente video. E io ho preso il posto come leader di questa parte del trajetto. Guardate, questo abbiamo già trattato un po'. Questo riguarda il deciso della ZBB, una spara di 2.000 euro per la costa di esploitazione della riuscita della comunità in 2023, e da 2024 2.500 euro. La risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risposta è che la risp L'ho informato il 15 novembre. Ci erano sei, che sono trasportati a tre, tre scenario di pre-cursi, in cui una consultazione del mercato è stata risolta, con l'obiettivo di guardare se una cosa era pericolosa. Non abbiamo presentato tutti questi scenario al mercato e ci siamo guardati, con tutte le possibili offerte per raccogliere tutto, ma cosa è pericolosa? E cosa contribuisce a creare di valore, in qualsiasi modo, nello stesso modo come cosa contribuisce a risparmiare le coste di esploitazione? 1 e 3 sono in principio vissibili. 2 è molto non sicuro. Quindi siamo andati a sviluppare, in ogni caso, 1 e 3. E con 3 vedremo subito perché 3, in nostra optica, gira di più. Quali erano i punti per cui siamo andati a sviluppare? C'è ovviamente l'uploadio delle strutture di risposta sull'exploitazione. Questo era il scelto della ZBB del 2021. |
Recognition by Whisper and Translations with DeepL
| Dutch (recognition) | German (translation) | English (translation) | Italian (translation) |
|
Dank u wel, wethouder. |
Vielen Dank, Herr Stadtrat. |
Thank you, councillor. |
Grazie, consigliere. |
Whisper Mic
Whisper Microphone
Friday 7 July 2023 was another new thing: how to use Whisper directly with your microphone.
Some clever guy has created a simple python script that allows you to turn your spoken speech directly on the screen as recognised text. Probably very useful for anyone who is going to use Whisper with Robots or experiments where direct feedback is important.
This is well explained in the accompanying (YouTube) video below.
Bottom line: the project is now pip installable. And you can easily install it by doing the following:
| pip install whisper-mic |
If that all went well, you can use it via:
| whisper_mic |