
Iedereen herkent het wel: iemand (vaak een wat vaag meisje) zit je aan te kijken en zegt: volgens mij denk jij xxxxxxx waarna er een betoog komt waarin wordt duidelijk gemaakt waar jij net aan zat te denken. Soms klopt dat, maar vaak ook niet en zat je met je gedachten heel ergens anders.
Maar zou het nu niet mooi zijn als dit toch zou kunnen? Jij denkt ergens aan en de ander weet dat dan direct? Mmmmmm….. Ja, maar persoonlijk houd ik mijn gedachten toch liever voor mijzelf (hoort u mij denken).
Deze mogelijkheid om iemands gedachten te lezen lijkt nu een beetje vervuld te worden.
Afgelopen week verscheen er een publicatie getiteld “Towards reconstructing intelligible speech from the human auditory cortex.” van het “Mortimer B. Zuckerman Mind Brain Behavior Institute” van de Columbia Universiteit in New York, waarin een onderzoek beschreven wordt waarvan de resultaten wel heel dicht in de buurt komen van gedachtenlezen.
 |
|
|
Luister hier het item terug |
Het onderzoek
De onderzoekers van de Columbia Universiteit hebben een systeem ontwikkeld dat het denken vertaalt in begrijpelijke, herkenbare spraak. De hersenactiviteit die gepaard gaat met het horen van woorden, wordt via een DNN (Deep Neural Network) omgezet in VoCoder-parameters die vervolgens de spraak in, voor dit soort onderzoek, ongekende heldere spraak omzet.
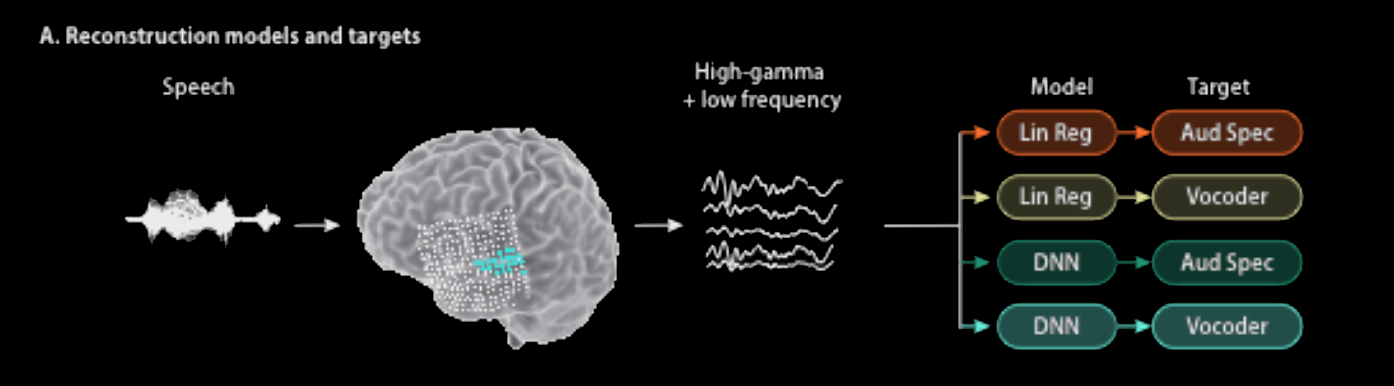 Schematische weergave van het Spraak Reconstructiemodel. Uit ”Towards reconstructing intelligible speech from the human auditory cortex” vanNima Mesgarani et all. (2019).
Schematische weergave van het Spraak Reconstructiemodel. Uit ”Towards reconstructing intelligible speech from the human auditory cortex” vanNima Mesgarani et all. (2019).
Bv. ik hoor “acht” → mijn hierbij optredende hersenactiviteiten worden opgevangen → een AI-systeem "vertaalt" dat in een set VoCoder-parameters → de spraaksynthesizer zegt “acht”.
Deze doorbraak kan leiden tot nieuwe manieren voor computers om direct met de hersenen te communiceren. Het legt wellicht de basis voor het helpen van mensen die niet (meer) kunnen spreken als gevolg van ALS (amyotrofe laterale sclerose) of een beroerte.
Taal en de mens
Taal is iets dat ons mensen onderscheidt van de dieren en wordt wel gezien als de meest typische menselijke eigenschap. Met taal communiceren wij met de wereld en vooral met andere mensen om ons heen. De input gaat via onze oren en, in het geval van lezen, onze ogen. De output gaat via onze spraak en, in het geval van schrijven, via ons schrift.
En natuurlijk hebben we meer mogelijkheden om ons te uiten (lichaamstaal, gebarentaal, geuren) maar spraak kan toch wel gezien worden als de van oudsher belangrijkste vorm om onze gedachten te uiten. En als dus onze spraak uitvalt, ontberen we een uiterst belangrijke manier om met de wereld om ons heen te kunnen communiceren.
De resultaten van het onderzoek zouden de basis kunnen leggen van een systeem dat mensen die niet kunnen spreken toch een stem te geven waarmee ze hun gedachten aan anderen kunnen verwoorden.
Spreekpatronen
De constatering dat spraak (daadwerkelijk uitgesproken of alleen maar in gedachte uitgesproken) bepaalde patronen in onze hersenen opwekken is al decennia bekend. Onderscheidende en herkenbare signaal-patronen komen ook naar voren als we naar iemand luisteren die spreekt, of als we ons het luisteren voorstellen. Maar het was tot nu niet gelukt om die patronen echt te vertalen naar begrijpelijk en verstaanbare spraak; dat bleek veel moeilijker dan gedacht. Eerder werden er pogingen gedaan met zogenaamde "lineaire regessie" methode maar dat bleek uit eindelijk niet te werken. De vertaling van hersengolven naar parameters die de VoCoder (spraaksynthesizer) correct aanstuurde bleek hier de bottleneck.
Deep Neural Networks (DNN)
Men is zich toen gaan richten op het vertalen van de hersengolven in VoCoder-parameters via DNN's. Hersengolven bestaan deels uit lage en deels uit hoge neurale frequencies en het was de vraag welke de relevante informatie bevatten. De resultaten tonen aan dat een DNN-model dat de VoCoder-parameters direct schat uit alle neurale frequenties de hoogste subjectieve en objectieve scores haalt op een herkenningstaak. De verstaanbaarheid wordt verbeterd met 65% ten opzichte van de basislijnmethode die gebruik maakte van lineaire regressie.
Deze resultaten tonen de effectiviteit aan van de combinatie van DNN's en spraaksynthese voor het ontwerpen van de volgende generatie spraak Brain-Computer-Interface (BCI) systemen, die niet alleen de communicatie voor verlamde patiënten kunnen herstellen, maar ook de potentie hebben om human-computer interactietechnologieën te transformeren.
Het experiment
 Om een en ander daadwerkelijk te testen, werd door Dr. Mesgarani (de hoofdonderzoeker) contact gezocht met neurochirurg dr. Ashesh Dinesh Mehta van het "Northwell Health Physician Partners Neuroscience Institute".
Om een en ander daadwerkelijk te testen, werd door Dr. Mesgarani (de hoofdonderzoeker) contact gezocht met neurochirurg dr. Ashesh Dinesh Mehta van het "Northwell Health Physician Partners Neuroscience Institute".
In samenwerking met Dr. Mehta vroegen ze epilepsiepatiënten die al een hersenoperatie hadden ondergaan om te luisteren naar door verschillende mensen uitgesproken zinnen. Tijdens dit luisteren werd de hersenactiviteit gemeten. Met de patronen van deze gemeten hersenactiviteiten werden de DNN's getraind. Vervolgens vroegen de onderzoekers diezelfde patiënten om te luisteren naar sprekers die cijfers tussen 0 en 9 voorlazen waarbij opnieuw de hersenactiviteiten gemeten werden. Die hersengolven werden door het getrainde Deep Neural Netwerk omgezet in parameters voor de VoCoder die op zijn beurt de spraak weer synthetiseerde.
Het eindresultaat was een robotachtige stem die een reeks getallen voorleest. Om de nauwkeurigheid van de opname te testen werden proefpersonen gevraagd de opname te beluisteren en aan te geven wat men hoorden.
Resultaat
Het verschil in resultaat tussen de oude manier via de Lineaire Regressie methode en de nieuwe manier via DNN's is redelijk spectaculair. Natuurlijk, moderne spraaksynthese klinkt veel en veel beter, maar dit is spraak die gemaakt is door onze hersengolven die we opwekken wanneer we naar de cijfers 0 t/m 9 luisteren te synthetiseren.
| Oude gesynthetiseerde spraak (0-9) | |
| Nieuwe gesynthetiseerde spraak (0-9) |
Die sterk verbeterde kwaliteit werd ook duidelijk in het luister experiment. Het bleek dat in 75% van de gevallen de luisteraars de gesynthetiseerde spraak correct konden verstaan: veel meer dan bij eerdere pogingen waarbij het geluid niet door een DNN was opgeschoond. De gevoelige VoCoder en krachtige neurale netwerken maakten geluiden (spraak) die verrassende veel leken op de geluiden die de patiënten hadden gehoord.
Toekomst
Van cijfers naar woorden naar zinnen
Nu dit redelijk lijkt te werken, zijn de onderzoekers van plan om meer gecompliceerde woorden en vervolgens zinnen te testen. Bovendien willen ze dezelfde testen uitvoeren op hersensignalen die worden “uitgezonden” wanneer een persoon niet luistert naar echte spraak maar zelf in gedachte spreekt (monologue intérieur).
Droom
Het uiteindelijke doel ligt voor de hand: een soort implantaat waarop dit systeem is geïnstalleerd waarmee de verbale gedachten van de drager van zo’n implantaat direct vertaald worden in al-dan-niet uitgesproken woorden. Het uitspreken is handig in een gesprek met ander mensen maar je kunt er ook andere dingen meedoen. Zo zou je je tekst direct op het scherm kunnen krijgen zonder tussenkomst van een spraakherkenner of zou je de domotica om je heen direct opdrachten kunnen geven als “doe de gordijnen dicht” of “zet de thermostaat op 18 oC”.
Het zou iedereen die door letsel of ziekte zijn spreekvaardigheid heeft verloren, opnieuw mogelijkheid geven om verbinding te maken met de wereld om zich heen.
Vragen
Het beschreven resultaat is behoorlijk gaaf maar roept ook wel een aantal vragen op. Wat heeft men nu precies gemeten? Is het de reactie van de hersenen op een binnenkomend spraaksignaal en zo ja op welk niveau? Is het de audio of is het de “vertaling” die de hersenen maken van het gehoorde signaal? Met andere woorden, is het de hersenreactie nadat het binnenkomende geluid vertaald werd naar een soort “object” (bv het cijfer vier).
En hoe zit het met de taal die de patiënten spreken? Geven de hersenen dezelfde patronen te zien wanneer een tweetalig iemand dezelfde cijfers hoort in zijn of haar twee talen (bv acht en otto)? Hoe reageert men op non-sense woorden of op woorden uit een andere taal die de luisteraar niet kent? Kortom: een fascinerend onderwerp waar we nog jaren veel mooi onderzoek aan kunnen doen.
Bronnen
Het oorspronkelijke, nog niet gereviewde artikel "Towards reconstructing intelligible speech from the human auditory cortex" kan hier worden gedownload.
Deze blog is gebaseerd op het oorspronkelijke artikel en een blog hierover op Techxplorer.