
![]() Herfst 2022 kwam er, na het een paar maanden daarvoor vrijgegeven Wav2Vec2 (van Facebook), weer een nieuwe spraakherkenner uit: Whisper. Deze software komt van het bedrijf OpenAI en is (opnieuw) een behoorlijke revolutie. Fout marges halveren (of beter) en de transcripties kun je behalve in de gesproken taal ook direct in het Engels krijgen. Ook is het resultaat inclusief punten, komma's en andere leestekens!
Herfst 2022 kwam er, na het een paar maanden daarvoor vrijgegeven Wav2Vec2 (van Facebook), weer een nieuwe spraakherkenner uit: Whisper. Deze software komt van het bedrijf OpenAI en is (opnieuw) een behoorlijke revolutie. Fout marges halveren (of beter) en de transcripties kun je behalve in de gesproken taal ook direct in het Engels krijgen. Ook is het resultaat inclusief punten, komma's en andere leestekens!
Whisper is als Open Source beschikbaar, heeft 9 "modellen" beschikbaar en kan in principe door iedereen gebruikt worden, mits...
Je hebt wel enige programmeerkennis nodig en natuurlijk een redelijk snelle computer.
Software
Er komen gelukkig steeds meer Open Source pakketten beschikbaar die Whisper "draaien". Zo is er SubtitleEdit (voor Windows) en MacWhisper (voor Apple) waarmee je je eigen AV-files uitstekend kunt herkennen. Let er wel op dat voor een snelle herkenning je eigenlijk een GPU nodig hebt. Bij de Mac zijn dat de nieuwe computers met een M1, M2 of M3 chip en voor Windows zijn dat de computers met een losse grafische kaart (een zogeheten GPU). Als je wilt weten of je computer een GPU heeft, doe je het volgende:
- Ga met je muis op de startbalk staan.
- Klik met je rechtermuisknop op die balk.
- Open taakbeheer.
- Er opent nu een tabblad, klik eventueel op ”meer details” en dan op ''prestaties''
- Hier vind je de GPU, ofwel je videokaart.
Whisper
Whisper wordt, zoals de auteurs het in het abstracht van hun paper schrijven, het best omschreven als:
Robuuste spraakherkenning via grootschalige zwakke supervisie
Alec Radford *1 Jong Wook Kim*1 Tao Xu1 Greg Brockman1 Christine McLeavey1 Ilya Sutskever1
* Equal contribution
1 OpenAI, San Francisco, CA 94110, USA
Abstract
We bestuderen de mogelijkheden om spraakverwerking systemen te trainen via eenvoudigweg grote hoeveelheden transcripties van audio op het internet. Wanneer geschaald naar 680.000 uur meertalig en multitask supervisie, generaliseren de resulterende modellen goed voor de standaard benchmarks en zijn ze vaak concurrerend met eerdere volledig gecontroleerde resultaten, maar dan in een zero-overdracht zonder de noodzaak van fijnafstemming.
In vergelijking met mensen benaderen de modellen hun nauwkeurigheid en robuustheid. Wij geven de modellen en inferentiecode om te gebruiken als als basis voor verder werk aan robuuste spraak verwerking.
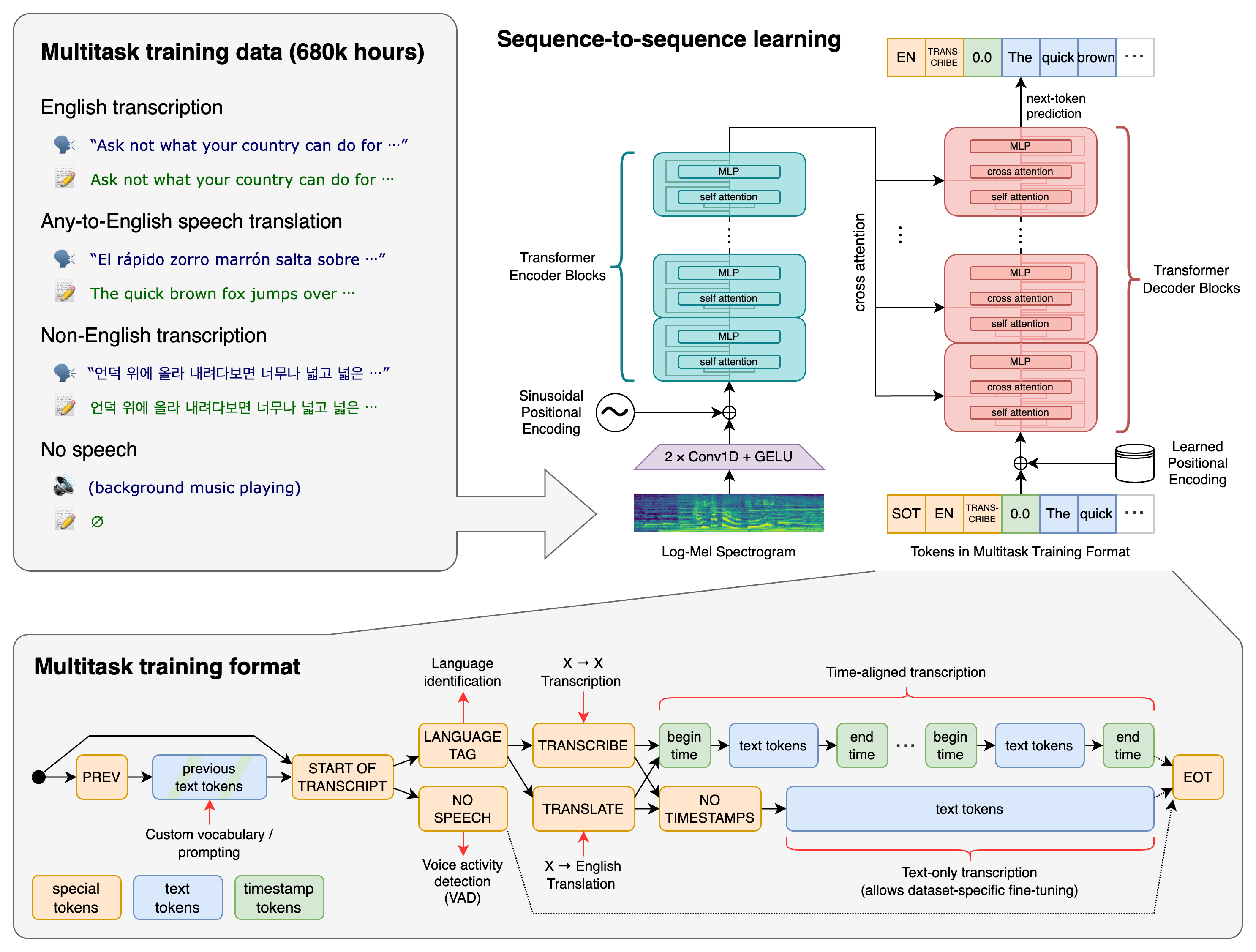 Overzicht van de werking van Whisper. Een sequentie-naar-sequentie Transformer-model wordt getraind op veel verschillende spraakverwerkingstaken, waaronder meertalige spraakherkenning, spraakvertaling, gesproken taalidentificatie en stemactiviteitdetectie.
Overzicht van de werking van Whisper. Een sequentie-naar-sequentie Transformer-model wordt getraind op veel verschillende spraakverwerkingstaken, waaronder meertalige spraakherkenning, spraakvertaling, gesproken taalidentificatie en stemactiviteitdetectie.
Al deze taken worden gezamenlijk voorgesteld als een reeks tokens die door de decoder moeten worden voorspeld, waardoor één enkel model vele verschillende stadia van een traditionele spraakverwerkingspijplijn kan vervangen. Het multitask trainingsformaat gebruikt een reeks speciale tokens die dienen als taakspecificatoren of classificatiedoelen.
Modellen
OpenAI heeft 9 modellen beschibaar voor Whisper.
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en |
tiny |
~1 GB | ~32x |
| base | 74 M | base.en |
base |
~1 GB | ~16x |
| small | 244 M | small.en |
small |
~2 GB | ~6x |
| medium | 769 M | medium.en |
medium |
~5 GB | ~2x |
| large-v1 | 1550 M | N/A | large |
~10 GB | 1x |
| large-v2 | 1550 M | N/A | large |
~10 GB | 1x |
| large-v3 | 1550 M | N/A | large |
~10 GB | 1x |
De voor mij belangrijke modellen zijn het medium en tegenwoordig vooral het Large-v2 model die beide goed draaien op mijn GPU (grafische kaart). Beide modellen werken zo goed, dat er eigenlijk niets meer te wensen over blijft. :-). Large v3 zou in principe het noog beter moeten doen, maar het lijkt erop dat v3 meer hallucinaties geeft.
SubtitleEdit
Hieronder een voorbeeld van het resultaat na gebruik van Whisper met de video van Pandora. Het is een video van ong. 3 min waarin een Nederlandse dame in correct maar niet-native Engels, een Brit aan de telefoon heeft. De herkenning en de vertaling zijn eigenlijk helemaal foutloos! Zowel de herkenning als de vertaling zijn gedaan met het Open Source programma SubtitleEdit.
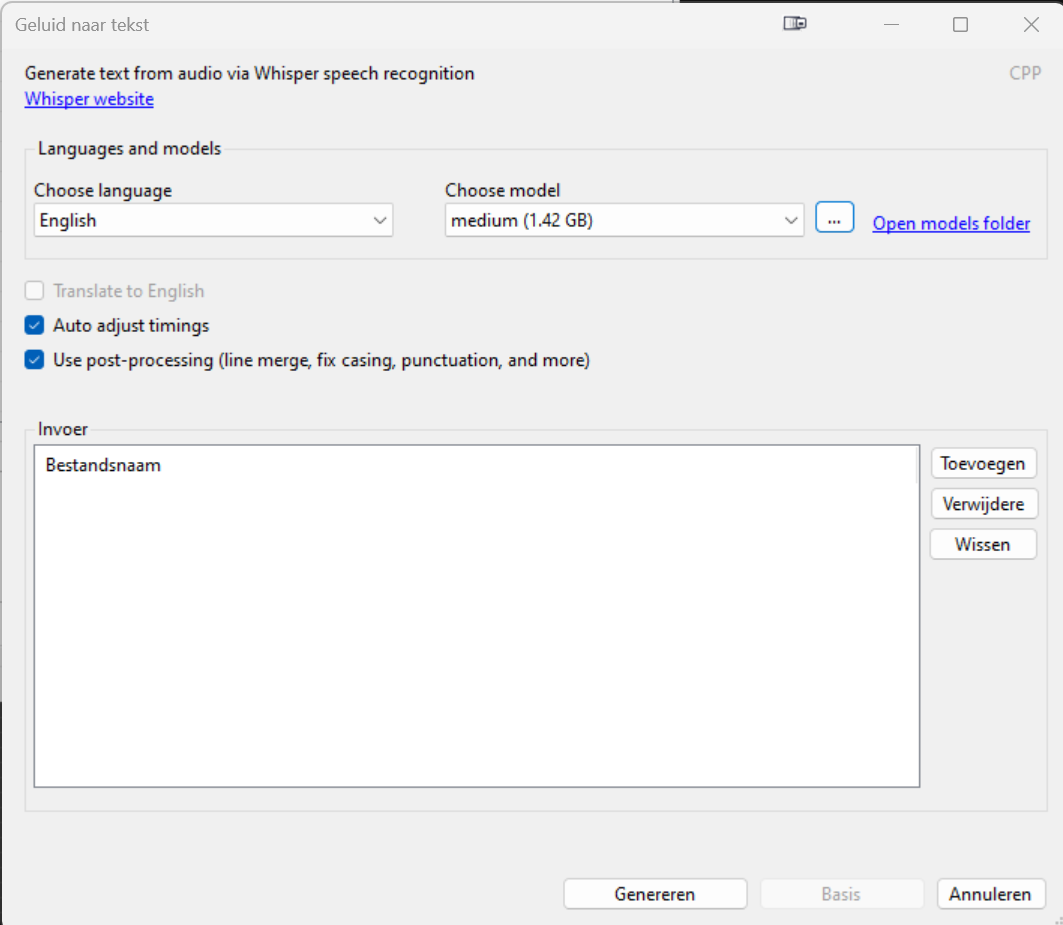 In het programma SubtitleEdit kun je vanaf versie 3.6.10 de transcripties door spraakherkenning laten genereren. Eerst (in een oudere versie) kon dat met Kaldi en nu ook met Whisper. Voor de "Pandora herkenning" hebben we medium model (1.42 GB) gebruikt. Op dit moment is mij nog niet helemaal duidelijk wat de relatie tussen herkenning en model-grootte is, dus misschien zou het ongeveer net zo goed gaan met een kleiner (en sneller) model. Het is iets dat we gaan uitzoeken!
In het programma SubtitleEdit kun je vanaf versie 3.6.10 de transcripties door spraakherkenning laten genereren. Eerst (in een oudere versie) kon dat met Kaldi en nu ook met Whisper. Voor de "Pandora herkenning" hebben we medium model (1.42 GB) gebruikt. Op dit moment is mij nog niet helemaal duidelijk wat de relatie tussen herkenning en model-grootte is, dus misschien zou het ongeveer net zo goed gaan met een kleiner (en sneller) model. Het is iets dat we gaan uitzoeken!
In SubtitleEdit kun je vervolgens de herkennigsresultaten (dwz de ondertiteling) laten vertalen in bv Nederlands. Dat wordt nu gedaan met GoogleTranslate.
Het enige dat nog niet helemaal goed gaat is de "tijd" waarop de verschillende ondertitels getoond worden. Soms begint het transcript bv. te vroeg, of loopt het juist te lang door. Ook worden sommige transcripties soms herhaald.
Hoe dan ook: de tijd-zetting van de transcripties kan in ieder geval sterk verbeterd worden door Forced Alignment.
In de volgende tab gaan we daar verder op in.
Pandora video met NL-ondertiteling
MacWhisper
 Naast SubtitleEdit (voor Windows) is er ook een Whisper-herkenner voor Apple: MacWhisper. Het is gemaakt door Jordi Bruin en gebaseerd op de door gemaakte C++ versie van Whisper. Het programma heeft en gratis versie die gebruik kan maken van de Tiny en Base modellen. Voor gebruik van de Small, Medium en Large modellen heb je de Pro-versie nodig: dat is één keer ong €20 betalen.
Naast SubtitleEdit (voor Windows) is er ook een Whisper-herkenner voor Apple: MacWhisper. Het is gemaakt door Jordi Bruin en gebaseerd op de door gemaakte C++ versie van Whisper. Het programma heeft en gratis versie die gebruik kan maken van de Tiny en Base modellen. Voor gebruik van de Small, Medium en Large modellen heb je de Pro-versie nodig: dat is één keer ong €20 betalen.
Net als de windows-versie, gaat ook hier de tijdcodering niet helemaal goed. Voor ondertiteling is dat dikwijls geen probleem maar voor onderzoek zou je wellicht wel nauwkeuriger tijdcodes van de woorden willen hebben.
 Hoe dan ook: het is een makkelijk te gebruiken spraakherkenner met uitstekende resultaten. In MacWhisper heb je bovendien nog allerlei toeters en bellen om de herkende tekst bijna perfect te maken. Kortom: als je een Apple hebt, ga er eens naar kijken.
Hoe dan ook: het is een makkelijk te gebruiken spraakherkenner met uitstekende resultaten. In MacWhisper heb je bovendien nog allerlei toeters en bellen om de herkende tekst bijna perfect te maken. Kortom: als je een Apple hebt, ga er eens naar kijken.
aTrain
In de herfst van 2023 kwamen onderzoekers van de Universiteit van Graz ook met een standalone spraakherkenner: aTrain. Deze draait echter op Windows en gebruikt naast Whisper, ook andere tools als WhisperX en Fast-Whisper. Dat zorgt ervoor dat je ook Sprekerherkenning (dwz Diarizatie) kunt doen en dat de herkenning (via Fast-Whisper) een heel stuk sneller is dan met de traditionele Whisper.
aTrain kan gedwonload worden via de Microsoft Store of via de BANDAS-Center Website. Het is wel een grote download (>10GB) dus het duurt even.
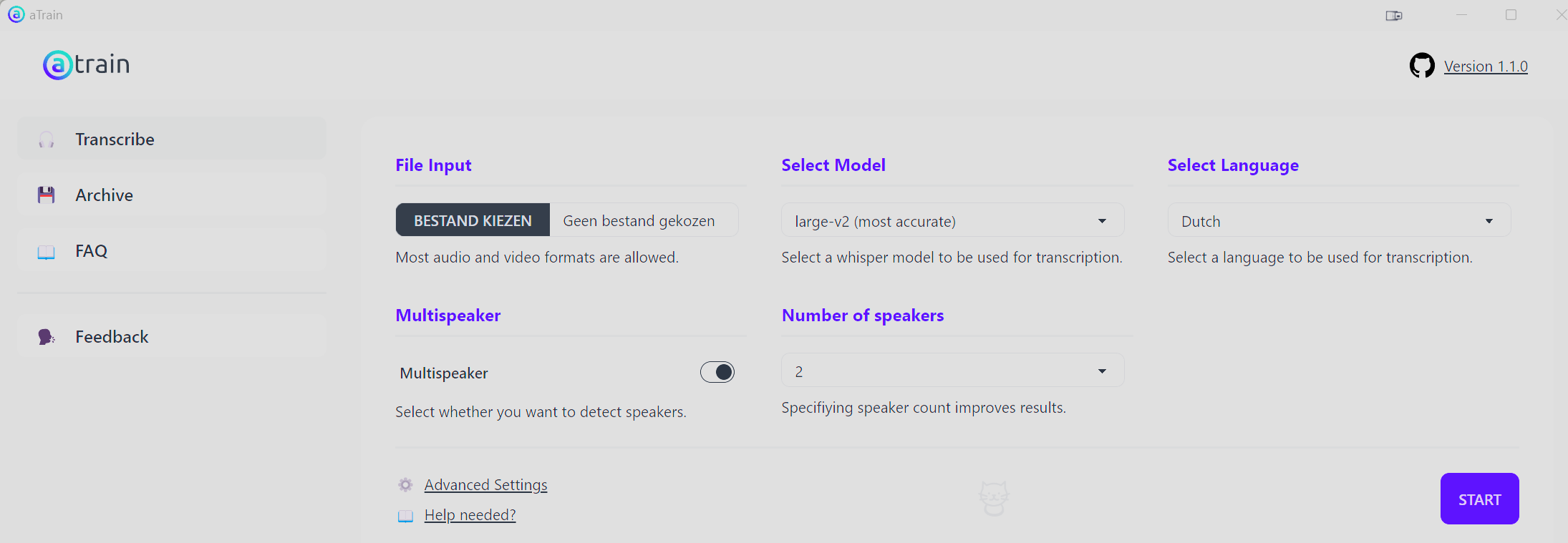
Na het downloaden kun je het installeren en vervolgens draaien. Je geeft de filenaam, de taal, het model en evt hoeveel verschillende sprekers er in de opnamen zijn. Dan klik je op start en wordt de AV-opnamen herkend.
De resultaten worden in een speciale directory weggeschreven.
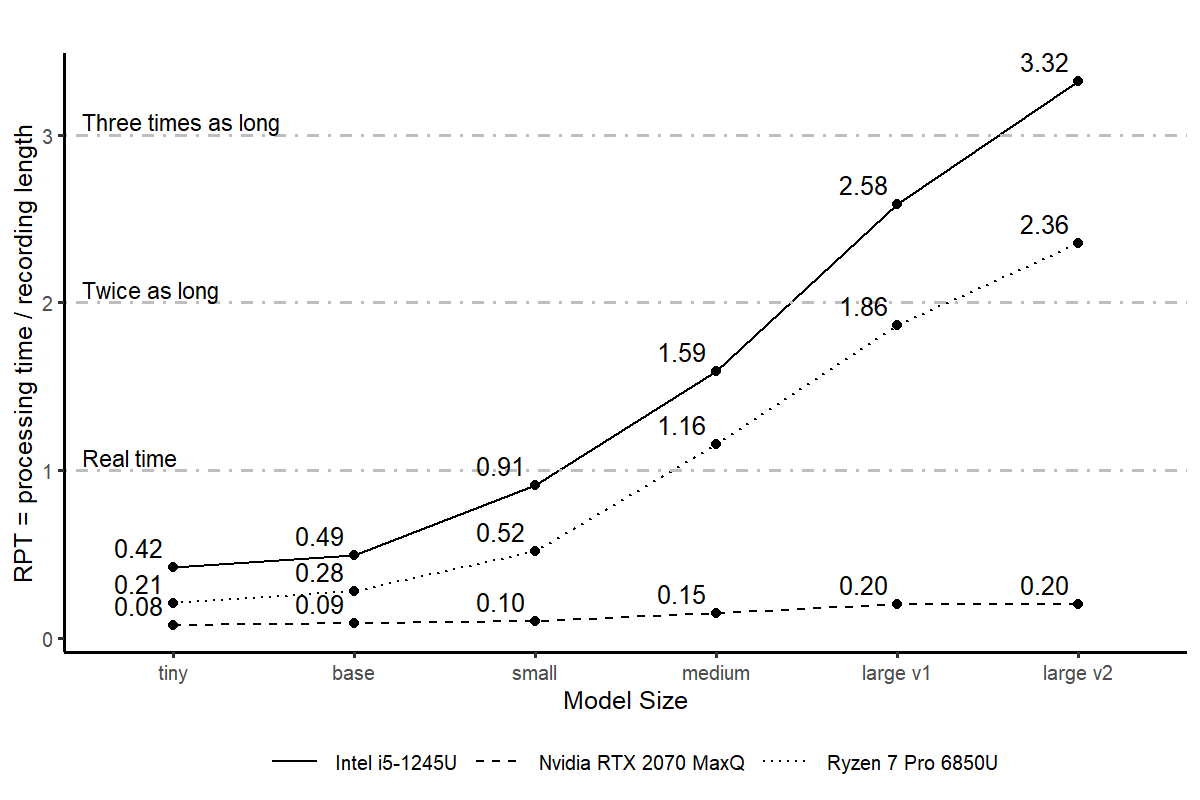
Het heeft zeker zin om wat te experimenteren met de verschillende modellen. Zeker, een zwaarder model geeft betere resultaten maar duurt ook (veel) langer.
Makers
 |
aTrain is ontwikkeld door onderzoekers van het Business Analytics and Data Science-Center van de Universiteit van Gräz en getest door onderzoekers van het Know-Center Graz. Meer valt te lezen in het originele paper:
Haberl, A., Fleiß, J., Kowald, D., & Thalmann, S. (2024). Take the aTrain. Introducing an interface for the Accessible Transcription of Interviews. Journal of Behavioral and Experimental Finance, 41, 100891. |
Conclusie
aTrain werkt goed, snel en is dus meer dan bruikbaar. Er is zeker nog ruimte voor verbeteringen zoals de mogelijkheid om een aantal files in te voeren en die vervolgens een-voor-een te herkennen, maar ongetwijfeld komt dat nog in een update.
Zelf Whisperen
In de tweede tab (SubtitleEdit) heb ik een Engelstalige video herkend en het resultaat automatisch vertaald naar het Nederlands. Dit werd allebei gedaan in versie 3.6.11 van SubtitleEdit en het werkt als een tierelier! Maar... het is uiteindelijk de bedoeling om Whisper (en een paar bijkomende tools) echt zelf te draaien op mijn eigen computer. Na een in eerste instantie vruchtloze poging is het begin februari 2023 gelukt om Whisper en WhisperX te installeren en daarmee een herkenning en vervolgens een (soort) Forced Alignment (FA) te doen!
Ik heb die herkenning gedaan met een video van de NTU. Dit is een 100 sec durende video waarin door verschillende Nederlandse en Vlaamse sprekers iets over het Nederlands gezegd wordt. Met één regel kun je de computer dan de video laten transcriberen waarna hij (?) vervolgens een Forced Aligment op de transcriptie toepast. Het resuultaat staat hieronder. Op een paar kleinigheden na, is het resultaat helemaal goed.
De WhisperX "toverregel" was:
|
whisperx Het_Nederlands_en_de_Taalunie.mp4 --model medium --output_dir . --align_model WAV2VEC2_ASR_LARGE_LV60K_960H --align_extend 2 |
Ik had echter vergeten om de taal op te geven (--language Dutch), maar whisper was slim genoeg om dat zelf te doen op grond van de eerste 30 sec spraak.
De resultaten die dit oplevert zijn een text-file, srt- en vtt-file, srt-word-file die ieder woord apart laat zien (incl de start en eind tijd, een soort cmt-file) en nog wat files.
Meer Whisper
Ondertussen is het gelukt om Whisper ook "gewoon" op mijn beide Macbook Pro's aan de praat te krijgen. En naast Whisper, kan ik nu ook WisperX draaien. Helaas heb ik een MacBook Pro met de "ouderwetse"Intel processor zodat ik helaas geen gebruik kan maken van cuda (=GPU). Met het gebruik van MacWhisper wordt dat probleem deels ondervangen doordat die niet gebruik maakt van Python maar de C++ versie. Daardoor werkt het met MacWhisper wel langzamer dan op mijn Windowsmachine maar sneller dan de combi Python en Apple.
Toekomst
Ondertussen lijkt Whisper voorlopig de wedstrijd voor optimale herkenning gewonnen te hebben. En dat houdt in dat ook anderen enthousiast geworden zijn en er meerdere Whisper-engines beschikbaar komen. Zo gaan we o.a. met de Radboud kijken naar het gebruik van Whisper voor Forced Alignment en Diarizatie. Op dit moment (Mei 2023) is dat een Kaldi-ding maar hopelijk gaat dat snel veranderen.